

In a nutshell, computer vision is the ability for computers to understand the world around them using visual data. In many ways, we take for granted just how complex computer vision is because our primary sense as humans is sight. Replicating a human’s visual system has proven to be a very difficult challenge and something that has only had significant progress in the past decade through the introduction of Neural Networks. Here we will explore why computer vision is important, why it is so tough and why mimicking nature through these Neural Networks has provided us with the best results.
Why computer vision is important
As with many engineering fields, we are interested in computer vision because of the potential to automate previously labour-intensive tasks. Let us take for example, screws being made in a production line. Each one of the screws will need to be manually inspected to check for any defects, such as dents. Checking every single screw would prove too difficult for any single inspector to do, so instead they would need to rely on a random sample and risk shipping some defective screws. With Computer Vision, we can build a stage in the production line where a camera detects dents in every single screw, ensuring that no defective products are ever sent to customers.
With new advances in computer vision techniques, we are seeing far more ambitious applications that could truly revolutionize our world:
- Auto-motives: Computer Vision is central to the future of autonomous cars and now we are seeing a huge amount of companies try to make this reality. We have seen multi-million-dollar start-ups (Zoox, Nuro, Drive.ai), tech giants (Nvidia, Apple, Uber) and car manufacturers (GM Cruise, Nissan, Mercedes-Benz) all actively testing self-driving cars on public roads in California. More near-term computer vision applications include automated safety, where a vehicle can keep a driver safe in case of a momentary lapse in judgement or they become incapacitated. For instance, computer vision can detect cars in a driver’s blind spot or ensure they are keeping safely within their lanes.
- Consumer devices: Those really popular filters used in apps such as Snapchat that have rainbows coming out of peoples’ mouths are all powered through Computer Vision running on our smart phones. Beyond making viral videos, computer vision is also a vital technology in Augmented Reality. Being able to place a virtual object in the real world, means being able to map the world accurately to know where the ground is or where a wall is, all of which is done by computer vision.
- Healthcare: As we face an ever aging population in many countries, the question arises of how can we take care of all these people. Future technologies will be focused on assisting healthcare professionals to make most effective use of their time. Computer Vision can be used for monitoring the elderly and detect if they have fallen or require other forms of assistance. Healthcare robotics can help from assisting nurses to cleaning hospitals and many of these robots will need to be able to navigate the world around them through Computer Vision.
- Industry 4.0: Often when talking about Industry 4.0, people mention how thousands of different sensors within factories will be connected, but what do we do with all this information? Computer Vision will allow the automatic processing of thousands of sensors that will help increase efficiency of our production lines through defect detection or automatic sorting.
Why Computer Vision is difficult
Changing images into information
When we see an image on a computer screen, what we are looking at is a matrix of pixels, where each pixel is a set amount of data. Each pixel is a different mix of the primary colours red, green or blue, where each colour is represented by a number between 0-255. The higher the number the more of a certain colour we mix in. This, perhaps unsurprisingly, mimics what happens in our eyes. In our eyes, we have cells known as Cones and these cells can be roughly divided into those that can detect red, green or blue. Through mathematics we can filter and manipulate these pixels into useful information.
What is useful information though? Well it depends on the context. Going back to our screw inspection example, a dent may always be significantly darker than the rest of the screw, so all we need to do to detect a defect is say that if the pixels are in a certain colour range then we have a defect. Similarly, we could do things like detect edges or features such as corners. We could look at if certain shapes such as circles or blobs appear. Why computer vision is so tricky is partly due to how large these images are. To process this information we need to go through every single pixel. In a HD image there are 1920×1080 pixels and each separate RGB colour value of a pixel is one byte long, meaning three bytes in a pixel. For a single HD image there is 6 megabytes worth of data. A video can often consist of 30 images in a single second, meaning that a single second worth of footage is 185 megabytes worth of data. To extract data from images is very memory and computationally intensive.

We need to decide what is important information and what is not, but it turns out that knowing what information is relevant is very difficult. Let us take the example of trying to recognize the squirrel in Figure 1, which shows various techniques we can try and apply to our picture to extract information. To recognize a squirrel, we can choose to look for the colour grey or we can look at its outline or maybe the outline of a bushy tail. The problem is that though, squirrels can be a lot of different shades of grey or not even grey at all depending on light conditions. The outline of a squirrel is also constantly changing according to the angle of the photo, so no single outline will do. Also, baby and fully grown squirrels have very different shapes. All these variations make deciding what is a squirrel very hard. We have a huge amount of information in a single image and choosing what is relevant is too difficult.
It is also worth noting that our brain does this process entirely automatically. When somebody points a squirrel out to us, it does not matter if we are seeing the squirrel from an angle or if the squirrel is red, grey or brown. Our brains are smart enough to recognise a squirrel. Maybe then, it should come as no surprise that the answer to this object recognition problem came from us copying how the brain functions, using Neural Networks.
The rise of Neural Networks

Whilst the use of Artificial Intelligence (AI) within Computer Vision has been around since the 1970s, it was not popularized until the ImageNet 2012 competition. The ImageNet competition gave participants a huge training database of 1000 different objects and asked them to build a program that could recognise those different objects in an unseen testing database. This was won by AlexNet beating other competition by a huge margin. AlexNet was a specific type of AI known as a Neural Network, which is modelled after the human brain.
An example of a Neural Network is shown in Figure 3. It consists of layers and layers of neurons that have thousands of connections to one another in a regular forward pattern. The image is inputted at the first layer and moves through each layer in turn, until the neurons in the final layer decides on what is in the image. What makes Neural Networks able to learn is that all these connections between neurons can either be strengthened or weakened. A strong connection will pass more data from one neuron to another whilst a weaker connection will suppress the amount of data from one neuron to the next. To recognise a squirrel there needs to be strong connections between neurons to form accurate pathways between the inputted image and the relevant output neurons.
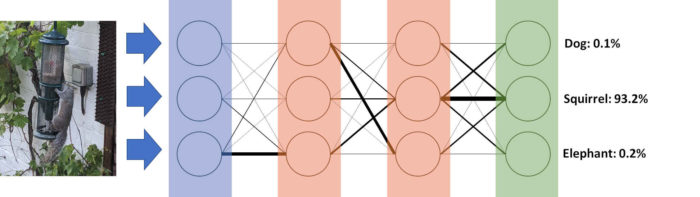
To strengthen or weaken these connections, we need to go through a training phase using a database of known objects. In the training phase, an image (for instance our squirrel) is passed through the Neural Network, which then guesses at what is in the image. In the final neuron output layer, there will be a neuron dedicated to each possible object, in this case we care about the neuron associated with squirrels. When a picture is passed through of a squirrel, the Neural Network will strengthen all the connections from the neurons where the squirrel is first inputted to the output neuron associated with squirrels. It will also suppress the connections that lead to all the other outputs. By providing enough examples of squirrels, eventually the Neural Network will pick up on the features that are important for recognising them. When it is accurate enough, we can stop the Neural Network from learning anymore and test it out on previously unseen pictures.
The accuracy of Neural Networks depends on the right connections to extract the right features and to form these connections requires two things. The first is training data. Simply put if we do not have enough data to train, the right connections can never be strengthened. The second is the amount of connections, which is controlled by the amount and size of layers in the Neural Network. If there are not enough connections, then the Neural Network cannot make meaningful pathways between the input and the output of the network. More connections requires more calculations meaning that a more powerful computer is needed.
By 2012, both setbacks had been solved. With the rise of faster internet as well as smart phones meaning that anyone could easily take and upload a picture, large scale image databases such as ImageNet were now possible. On top of this, high performance hardware chips known as Graphics Processing Units (GPUs) made processing power cheap and available, making the training of AlexNet possible.
Once the potential of Neural Networks had been shown, they exploded in popularity. Today’s Neural Networks can not only produce the probability of a single object in a photo, but also identify the position of multiple objects with pixel perfect precision. Neural Networks have even proven effective in other computer vision tasks, such as the ability to increase the resolution of a photo or even stabilize shaky video footage.
With the advent of Neural Networks, computer vision has entered an exciting period of innovation where limits are still being pushed and new applications are found regularly. This era was brought on by the mass availability of data and cheap computing power that enabled the training of Neural Networks with enough depth to extract the important features from images. These Neural Networks mimic how the human brain works and learn what information in a photo is relevant for identifying objects. This method has proven far more effective than previous attempts that relied on us manually trying to extract the relevant information from the large amount of data present in photos. These new methods can make a huge impact in a range of industries from recognising filters on smartphones to defect detection on factory production lines. The ability for computers to learn and understand the world through visual data will truly shape the future of technology.