Check out our new short presentation on how BeetleboxCI provides whole application acceleration to AI, keeping with innovation far faster than other silicon chips:
https://beetlebox.org/wp-content/uploads/2021/11/BeetleboxCI-for-Artificial-Intelligence.pdf
The speed of AI innovation is outpacing silicon chips. FPGA Accelerators are the solutions. Here at Beetlebox, we envision a future where reconfigurable hardware is used to optimise not just the AI but provide whole application acceleration.
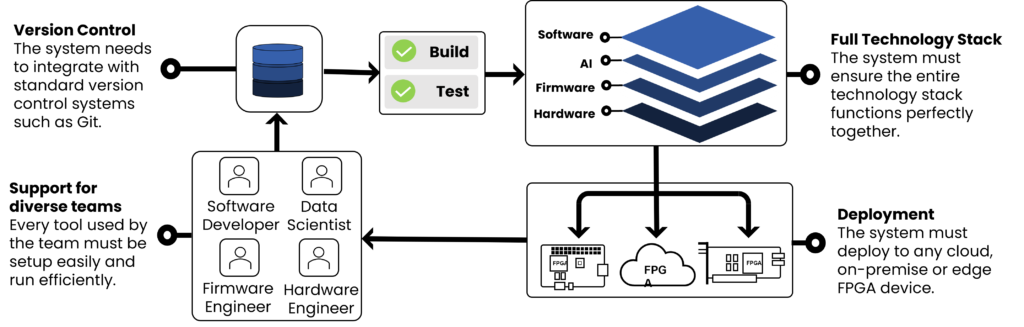
Cutting-edge whole application acceleration relies on constant improvement. To keep up with AI innovation accelerated systems must have short development cycles, constant updates and increased testing and dependability.
Constant improvement requires automation. To keep constantly improving, we need a system that can automate the entire development process from individual’s developers code to final production.
Automating should be simple, scalable and cost-efficient.
| Simple | The development team needs to be focused on their sections, not on trying to manage their infrastructure. |
| Scalable | Running across an entire technology stack requires hundreds of tests that have different computational demands. Servers need to scale with this demand. |
| Cost Efficient | The solution should not need large investment in infrastructure nor spending months configuring a cloud to a team’s needs. |
We believe the solution is BeetleboxCI. Design, develop and deploy AI with the automation platform for FPGA accelerator design.
| Simplicity | Native support for FPGA development tools with no need for any infrastructure setup. |
| Scalability | BeetleboxCI is designed to handle all stages of development from one or two prototype tests to weeklong simulations. |
| Cost-efficiency | Developers are only charged for what they use and do not need to invest in costly infrastructure. |

BeetleboxCI supports an iterative process that allows developers to accelerate each section of the system within a managed environment, whilst also building and testing the entire system.
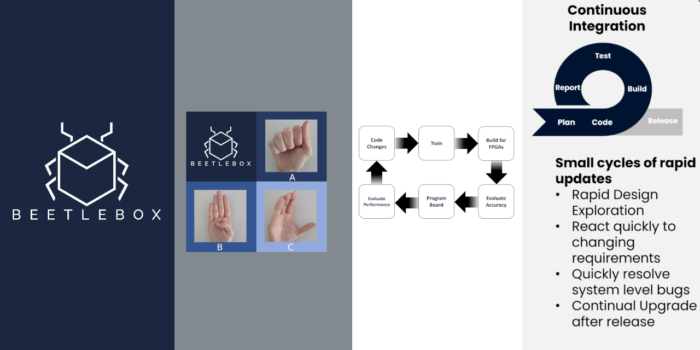
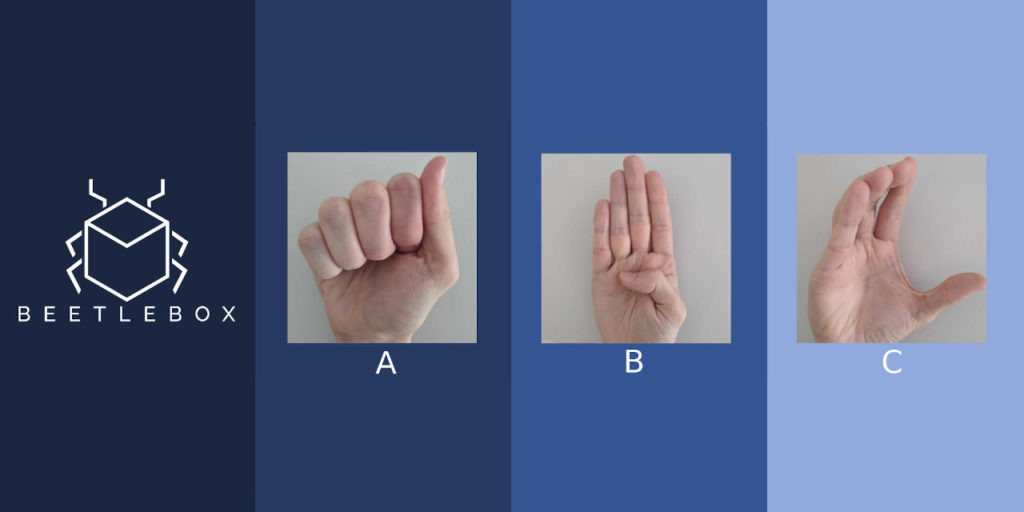
Example Design: Sign Language MNIST.
Challenge
Based off the original MNIST dataset, the sign language MNIST dataset contains 27,455 examples of 24 letters (excluding J and Z).
The challenge lies in correctly identifying these letters in a cost efficient manner to provide pragmatic help to the deaf and hard of hearing.
Solution
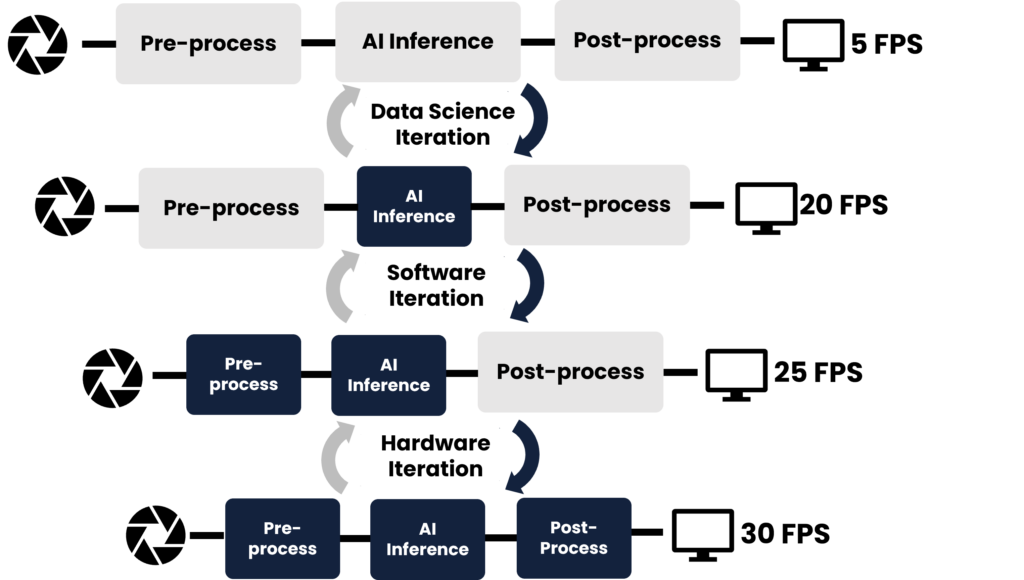
Using BeetleboxCI, we designed a simplistic neural network that can easily be trained on a CPU.
The design of neural networks is an iterative process, based on making improvements to the code and dataset itself. Our automated pipeline would retrain the neural network, quantize and prepare the files on FPGAs within three minutes of submitting a change to the code repository.
Result
On a ZCU104: •Throughput : 1067.21 FPS •Accuracy : 92.95%
Entire project is available as open source and can be setup in as little as twelve steps:
https://github.com/beetleboxorg/sign_language_mnist
Get Developing Now
Get started for free on our website with 10,000 free credits: beetlebox.org