

Introduction
In our previous tutorial series, we looked at sign language recognition using the sign language MNIST dataset based off the original 1999 MNIST dataset, which is considered the “Hello World” of machine learning. We did this because we wanted a practical example that could be trained on a standard CPU. The sign language MNIST still has the same characteristics of the other MNIST datasets which is that the images are all greyscale and low resolution (28×28). The weaknesses of this format of dataset became apparent throughout its usage and since many of the characteristics are shared with MNIST, we thought this would be a good opportunity to highlight the weaknesses of MNIST and how we can create better performing CNNs. We will also look at the quality of the dataset and provide tips for improving it.
The weakness of the MNIST datasets
We managed to push the testing dataset accuracy to about 97%, but when testing using ‘in the wild’ data none of our top-1 results were correct, so how can we improve our CNN? Poor performance of ‘in the wild’ testing is indicative of a bad testing dataset. Essentially our testing dataset is too controlled. An ideal dataset should consist of practical examples that we will meet out on the field, meaning that we want a dataset that consists of a variety of lighting, different hands and rescaled images. The original dataset consists of 1704 images, mostly consisting of a small amount of people all in the same office environment under the same lighting conditions, which makes for a poor dataset. Since 1704 images is not enough to train a CNN, the dataset was extended by creating 50+ variations of a single image through varying filters, random pixilation, varying brightness and varying rotation. Varying data like this does not create the same level of diversity as a good dataset and so whilst it seems that we have a large amount of training data, we only have tens of images providing good training. Compare this to the 330K of original images in the COCO dataset and it is clear to see why our CNN may struggle with ‘in the wild’ testing.
If we were to improve our CNN, the very first thing we need to do is improve our dataset. We can look at using other American Sign Language datasets, such as this one that contains 87,000 images. Unfortunately, there does not appear to be a definitive dataset for the American Sign Language and they seem to suffer from the same issues as we have experienced with our database (lack of variety of hands in different environments). Combining multiple datasets together can help overcome this issue though, as each dataset will have different hands in different environments.
Image scrapping is another popular technique for machine learning, where we simply ask a search engine to do the hard work for us. Bing even has an API to make this easier to do. Sign Language images are difficult to scrape because not many people are posting individual letters of the alphabet and mostly we get diagrams, so without serious amounts of pre-processing to recognise and separate hands, we are out of luck.
The best choice we have is to create fresh data from scratch. Does that mean we need to gather all our family and friends and start taking photos of their hands? Well that is one way of doing it, but it is not particularly scalable. Instead we can utilise crowd sourcing (Clickworker, Amazon’s Mechanical Turk) to create jobs for others. We need to time how long it takes us to do the entire alphabet and upload the files. Using that information, we can then create a task with the appropriate timing and since people will be taking photos in all sorts of different environments at different times of the day, this should significantly improve our dataset.
By having a testing dataset that is more indicative of the types of images that we will face ‘in the wild’ we can get a better understanding of our accuracy. Once we have that, we can then start focusing on our training dataset, looking at things like image pre-processing and variations to try to improve our performance. In many ways the testing dataset is more important than the training because without a good testing dataset, we may not even know we are going wrong.
Poor Resolution

Another major contributing factor to our lack of accuracy was our poor resolution. Poor resolution removes the fine-grain features the neural network will need to distinguish between signs. We want higher resolution, but resolution is one of the greatest determining factors on the size of our neural network. The larger the resolution, the larger the neural network, the more time taken for training. Since we were training on a CPU, having a large resolution was not really viable so we stuck to the classic 28×28. If we are looking for greater accuracy ‘in the field’ though, we need to ask what resolutions are we likely to be seeing? For Sign Language Recognition, we are likely to be looking at applications such as video conferencing or communicating with reception robots and in these areas we will be receiving high resolution images. A good rule of thumb is to use images around 256×256, but I would recommend starting off with 96×96. To decide on an optimal size we would need to perform an investigation to find optimal tradeoff between performance and accuracy.
Greyscale vs colour
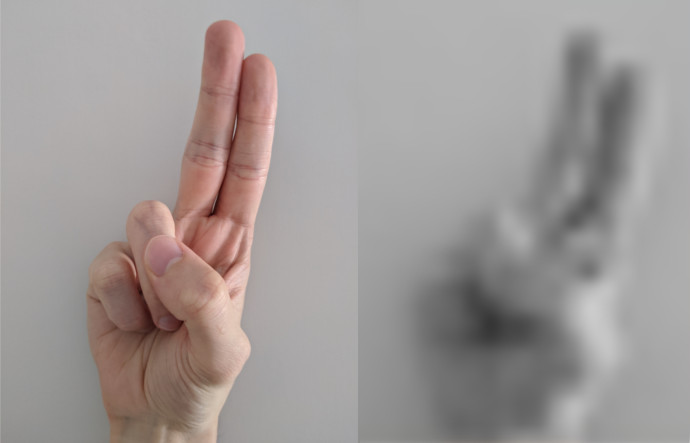
Another computational cost cutting technique we used was to convert our images from colour to greyscale. Most important information in an image is held within the greyscale. As humans we can easily tell that a hand is a hand in a grey image. Greyscale images tend to be three times smaller than the same RGB images, meaning it can be used to decrease the number of parameters allowing for less training. In a situation where we do not have much good quality training data to begin with, less required training is great for us.
The impact of this though is that we provide less information to the neural network. Hands are all a natural flesh colour which can easily stand out against backgrounds. By removing that information, the neural network can no longer associate flesh colours with hands and use that to distinguish hands and their backgrounds. This is especially important as the silhouette of the hand can be used to determine the sign we are using. Also three times as many input neurons can be significant if we are dealing with small neural networks but it is quite negligible compared to the number of parameters in large modern neural networks, so any parameter savings may have no impact whatsoever. On top of this, if we gather a better dataset we reduce the risk of overfitting with a larger neural network.
Conclusion
In our original tutorial we were posting accuracies of 97%, but when we tried to apply images that represented data ‘in the wild’ we noticed that none of the results were correct, indicating a problem with our dataset that is often seen with MNIST-like datasets. If we were to improve our CNN, our first challenge is to make our testing dataset more representative of images we will find in practice. We noticed that the dataset we had was actually based off varying a small amount of images all of which used the same people multiple times with similar backgrounds. This pointed to fundamental problems with our datasets and we have suggested the easiest way to improve the dataset would be through crowd sourcing.
Once we have better training and testing datasets, we can also look to improve the CNN accuracy through improving the resolution, which will give the opportunity for our CNN to learn the more fine-grained features of signs and help better distinguish between signs. Finally, we recommend swapping training from greyscale to colour as greyscale removes some of the information form the photos that could otherwise be used to help the CNN learn features. These improvements will help the base performance of our simple CNN, but deep learning has come a long way since these basic image recognition CNNs. In our next post we will be looking at the current state of the art technology and seeing how we could apply this to improve our sign language recognition.


