
Continuous Integration (CI) and Continuous Deployment (CD) are the most important practices in modern software development. In fact, 44% of developers regularly use CI/CD. Yet despite CI impact on software developers, it has not been widely adopted within the embedded systems industry.
A large reason for this lack of adoption is because embedded engineers do not know where to get started. They have heard about the benefits of CI, but what does a practical system look like?
We will be taking a deep dive into a basic structure of CI for embedded systems that we widely recommend to our customers. We will be looking at the overall architecture and the core components of CI. During this discussion, we will also look at how the embedded CI flow might differ from the standard systems software developers are familiar with.
First let us gain a better understanding of CI.
What is CI?
CI is the practise of frequently merging developer code into a single central repository that is then automatically built and tested. In fact, in one of our previous articles we cover the history of CI and why it was developed in the first place. CI is both a set of tools and practices that need to be in regular use.
CI took off in the software development world as it formed a core part of Agile development. Agile development is a framework that breaks down the development flow into iterations, often called sprints.
Instead of spending months designing, developing and then testing a product in a linear fashion, Agile is designed to split a product into its essential components that are then delivered iteratively. This enables developers to get their products to customers much faster and begin receiving feedback sooner.
To properly perform Agile though, developers need to be secure that the code they are rapidly updating is correct. This is why CI is so crucial. It can run builds and tests against that quickly changing codebase, ensuring that new bugs are not introduced and allowing developers to release new updates with confidence.
The basics of a CI system
At the very least, every CI system will consist of the following:
- Version Control System (VCS). A VCS is a software tool that allows developers to track and manage the changes that are made to a source code over time. This source code is held in a code repository. An effective VCS allows hundreds of developers to work on the same code base without breaking each other’s contributions. Popular VCS tend to be Git based and include GitHub, GitLab and BitBucket.
- Build and test automation. A CI system will run through all the basic builds and tests that are needed before a product can be deployed to customers.
- Deployment pipelines. Once a product is built and tested, it is ready to be deployed to customers. For most software development this will involve updating production servers or pushing updates through to an app store.
- Reporting and Monitoring. Since CI does not stop when a product is released to customers, it is important that developers continually monitor their product through collected data and metrics. Common metrics that are watched include uptime, error rate, lead time and infrastructure costs.
Here at Beetlebox we specialise in embedded DevOps. Using these core concepts, we have created a CI flow that works great for embedded systems. Often, we like to explain CI in terms of how a factory should work.
How CI works: The embedded software factory
One powerful way to think about CI is like a factory. Efficient factories consist of automated pipelines that take basic components and produce a working product at the other end. We want to minimize human involvement to increase productivity.
A fully automated factory can run 24 hours per day 365 days per year and can even self-adjust and measure the quality of their products. This results in improved productivity, quality, consistency, reduced waste, safer working conditions and cost savings.
A great CI system is a fully automated factory. It can efficiently take source code made by developers and deliver it to customers rapidly and bug free. It’s what we strive to deliver to our customers. If you’d like to put us to the test, you can book a demo with us here.
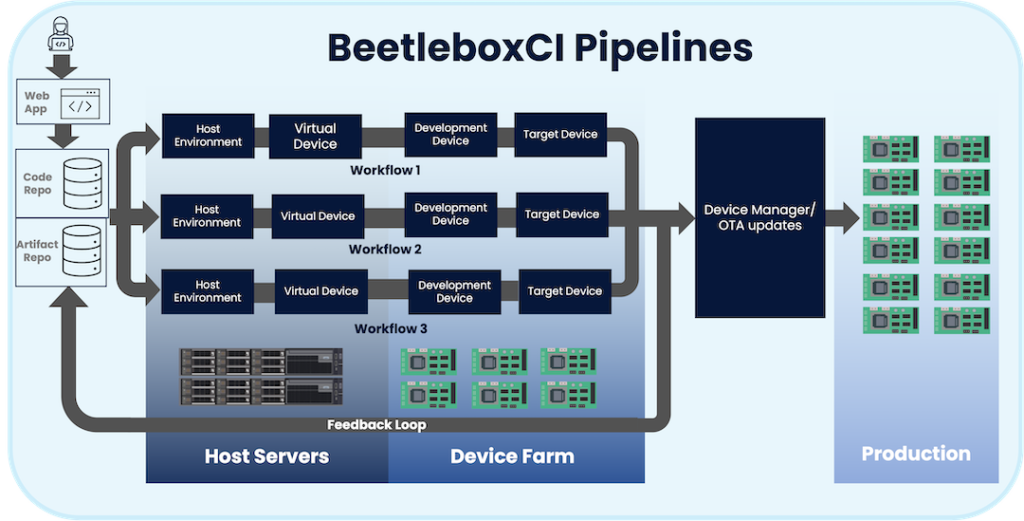
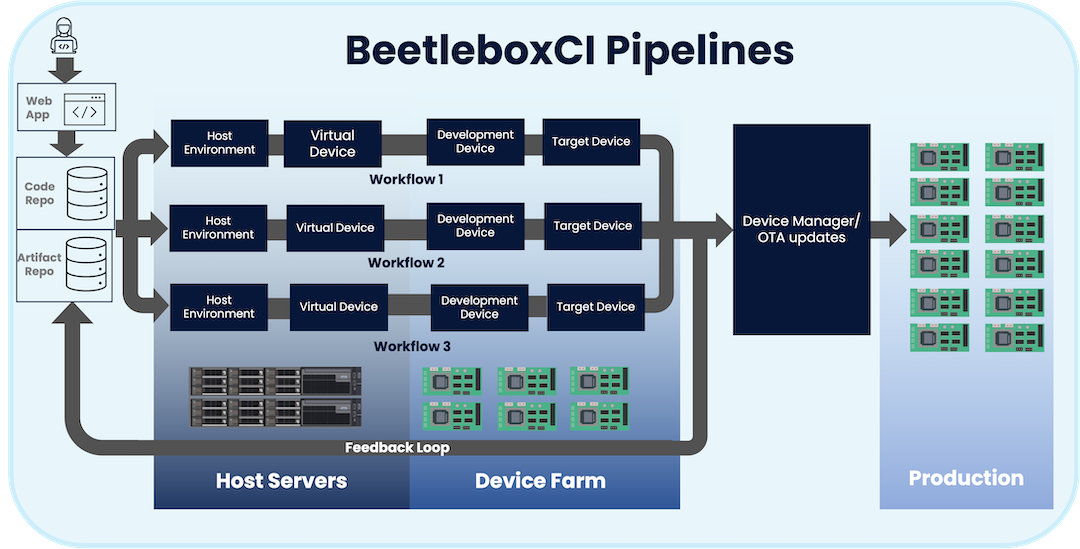
In diagram above, we show an example of an effective CI system using our tool BeetleboxCI. This setup consists of a pipeline made of three automated workflows that take code that is held within a code repository and automatically build and test that code. The resulting built software is then sent through to a Device Manager or Over-the-air (OTA) update service before being used to update devices that have been released to production customers.
A developer team interfaces with BeetleboxCI in two basic ways. The first is that they can create configuration files that are held within their code repository, which BeetleboxCI uses to create and update the pipeline. The second is that they can use the BeetleboxCI webapp to monitor and manage the pipeline.
What is a CI pipeline?
A CI pipeline is the most basic building block of any CI system. It is a set of automated processes or workflows that the developer uses to build, test, and deploy the code changes that have occurred.
A developer can build a pipeline by placing a configuration file inside the code repository that BeetleboxCI can then read. BeetleboxCI will then create the pipeline according to the specifications held within this file.
In our scenario, the pipeline consists of three workflows. These workflows will catch any bugs that are accidently introduced by the developers as they work, ensuring that our embedded devices remain in a stable working state.
Often pipelines are made of multiple workflows because the developers may want to slightly modify the flows for the same source code. These modifications could involve using different tools or testing frameworks.
Every workflow has access to the same code repository as well as the artifact repository. The artifact repository is a storage system that holds various files that workflow might need to complete build or test. It will also hold the files that are produced by the build and test process. This may be things like:
- Compiled Binaries
- Third party libraries or dependencies
- Test results
- Configuration files
- Test input data
Any workflow can be triggered by either a developer manually triggering them through the BeetleboxCI webapp, by new code being committed to the repository or at a user specified time or date.
Each workflow is split into specific tasks or set of related tasks known as jobs. Every job runs in an independent, clean execution environment known as a runner. These runners can use different OS and are isolated from one another. In our example, a pipeline has four jobs to run: Host Environment, Virtual Device, Development Device and Target Device.
These four jobs highlight some of the unique characteristics of BeetleboxCI and what sets us apart from other CI providers who are not focused on embedded devices.
Host Environment
Our workflow begins with running our code on the host server. This job will be the most familiar part for software developers who have worked with CI before. The job will run in an isolated container on the server. It will generally involve compiling the software and running through basic tests.
This step is generally very efficient and scales effectively. The problem though is that it is not very accurate for simulating what an embedded device may do as the software is compiled to run on a server not to run on our devices, which will cause differences in results.
It may also be difficult to run key parts of an embedded system on a host server, such as firmware or device drivers.
Virtual Device
A virtual device job is a software-based emulation or simulation of the physical embedded device, we wish to run on. This software emulation runs on the host server. These devices mimic the behaviour and functionality of the actual hardware device without the need to own the devices themselves.
This job has the advantage of running multiple tests simultaneously far cheaper than running on actual embedded devices and provides more accurate testing than just running on the host environment.
The downside is that virtual devices job tends to be much more system intensive and takes far greater time than running on a host environment and may not perfectly simulate conditions.
BeetleboxCI has built in Devices features that make it easy to automatically launch and connect to virtual devices. We also have extensive documentation on a range of emulators and simulators that can be used in our pipelines.
Development Devices
Often at the beginning of an embedded system project, software developers may need access to the devices that are still being developed. A good alternative to providing this access is through using the development boards provided by the chip manufacturers, such as the STM32 Nucleo Boards.
They can provide a quick of prototyping and enable access to the exact chips that will be used before the hardware team have even created their first designs. BeetleboxCI can be used to manage and orchestrate these devices by connecting them to the host server.
BeetleboxCI can then automatically handle the communication, file transfer and testing on these devices.
When developers have access to a wide range of these physical devices, it is called a device farm. The disadvantage of device farms is that they scale poorly, and it can be difficult to run hundreds of tests that a developer may want to without building a large farm.
Target Devices
Once hardware developers start providing batches of devices, these devices can also be managed and orchestrated through BeetleboxCI. It can then run the necessary builds and devices for these tests.
The advantage of using target devices is that it is identical to what will be provided to the customer and tests are generally faster than virtual devices. The disadvantage though is that this step has the highest upfront costs and hardware can still be limited depending on manufacturing budget.
Once this stage has finished, the developers then have access to the tested compiled binaries and files need to configure the final devices. These files along with any test data are then stored back into the artifact and code repositories, where they can be used by developers as part of the feedback for the next development iteration.
Device management and OTA updates
Finally, if the workflow manages to pass all the previous stages, BeetleboxCI can feed the created files into a device manager or OTA update system, such as Mender or Balena.
These systems can then safely and securely deploy the updates to production devices that are with customers. Completing the entire CI/CD cycle for embedded systems.
Conclusion
Whilst engineers in the embedded sector recognise the potential for CI in their development cycles, they often struggle to get started. Here we present an example CI system that consists of a single pipeline made of three workflows.
Each of these workflows is connected to both code and artifact repository that supply the source code and files needed. These workflows consist of four jobs. The host environment, virtual devices, development devices and target devices.
After these jobs have finished, embedded developers can confidently release to production devices through their preferred device management or OTA service.
As embedded devices and the IoT expands, efficient development and management of these devices is crucial. Through BeetleboxCI developers can gain the benefits of CI, which has been previously limited to software developers, without spending years developing their own systems or architectures.
You can also learn more about BeetleboxCI from our webinar that you can join here.

