22 Sep
Part 1: Introduction
Welcome to our multi part tutorial on using Vitis AI with TensorFlow, Keras and BeetleboxCI. This tutorial series is designed to teach the entire development process from initial code to forming an entire Continuous Integration pipeline that can be used for rapid testing and deployment of code.
Throughout this series, we will be covering:
- Why use FPGAs for AI?
- Unlocking FPGAs power and flexibility with Continuous Integration.
- Getting started with Vitis AI with TensorFlow 2 and Keras.
- Getting started with Continuous Integration with BeetleboxCI.
- Learning how we can improve our AI.
You can also start a discussion or raise any issues with the code through the GitHub page.
You can sign up for BeetleboxCI for free here.
You can also find out more about BeetleboxCI here.
Overview
The tutorials are focused on Sign Language recognition using Vitis AI to translate models built in Tensorflow and Kaggle, explaining both the theory of why and how we use FPGAs for AI and the practise of implementing it. The dataset was chosen because it is small enough to allow for quick training on CPUs. This is the second in a multi-part series, but is also the perfect place to begin:
- (Here) Part 1 – Introduction: Why use FPGAs for AI? Why Continuous Integration for FPGA technology.
- Part 2 – Quick Start Guide: Get going in twelve simple steps.
- More coming soon…
Why use FPGAs for AI
FPGAs have been around for decades but there has been renewed excitement around them thanks to AI, but why consider using AI on FPGAs over other chips such as GPUs. There are three reasons:
- Computing Efficiency
- Power Consumption
- Future Proofing
Computing Efficiency
FPGAs are computing efficient because of their high customisability combined with high amounts of dedicated arithmetic hardware blocks. This allows us to customise the hardware to our specific AI architecture. If we need a hardware accelerator that can achieve low consistent latency, we can build FPGA designs to meet those needs. Fundamentally, no other chip has the flexibility or computational power to accomplish this.
Power Consumption
FPGA technology provides high performance per Watt especially when compared to GPU technology. This makes them highly advantageous when applications are power limited in both the embedded and data centre sectors. In the embedded sectors, we often want to have powerful AI run in a specific power budget, as is often the case in wearables or robotics. Data centres are also often power limited due to the limited supply server racks can deliver. Power consumption also determines the cooling requirements of the servers.
Future Proofing
We also have a degree of future proofing that other chips cannot match. AI is a constantly evolving field and often changes in software occur too quickly for hardware accelerators to catch up. FPGAs can provide a needed boost in performance whilst also adapting to the latest and greatest AI techniques. Also, the chip does not need to be devoted to AI alone, meaning if you need to perform other tasks alongside AI, it can accelerate those tasks as well. When we combine the flexibility of FPGAs with Continuous Integration techniques, we have powerful future proofing.
Unlocking FPGAs power and flexibility with Continuous Integration and BeetleboxCI
Much of the advantage of FPGAs come from their flexibility, but many traditional development methods, such as Waterfall, fail to take advantage of this.
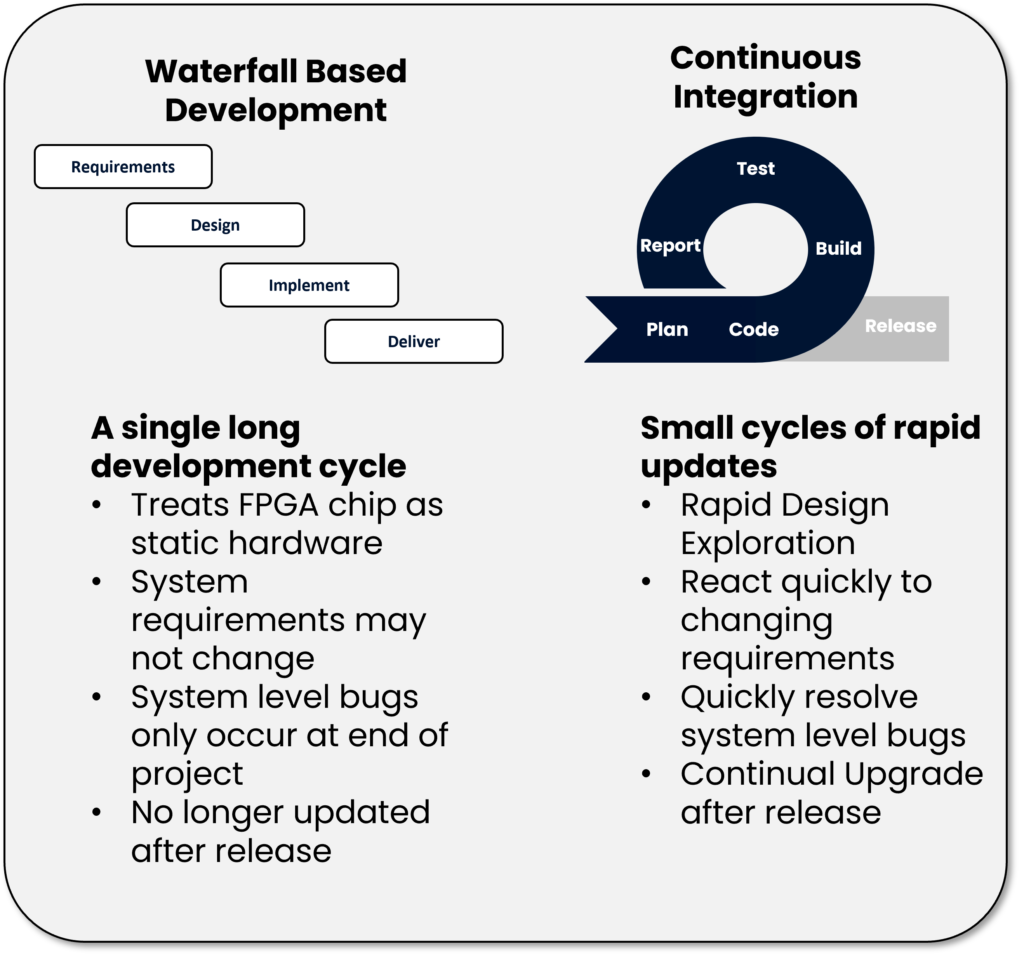
The waterfall model treats FPGA design as a single long development cycle beginning with defining the client’s requirements and creating FPGA designs around those requirements. Often these FPGA designs are separated into different modules. Designers and verification engineers will then implement the modules one by one until a final integration of all these modules at the very end. Modules are verified by scripting them and running on local servers. Once verified, the completed design is then sent off to customers. This process mimics other hardware-based engineering projects and treats FPGAs as a single static hardware system that is unchanging once implemented.
There are many issues that arise when using the Waterfall model. It is reliant on customer’s requirements remaining unchanged for months no matter how their industry shifts. This is especially unrealistic given how quickly software and AI markets vary from year to year. If designing for FPGAs is to remain relevant, we cannot carry on with Waterfall.
Moreover, much of the risk of the project is left till the end at final integration when system level bugs emerge. At this point, changing the system is at its most costly. When developers compare using FPGAs to other chips, this associated risk makes them highly unattractive to adopt.
For FPGAs to become appealing to modern developers, it is important to embrace its reconfigurability and combine it with Continuous Integration (CI). CI is where developers commit small changes to a single shared code repository. This code repository is then built, tested and deployed through automated systems. CI encourages development to take place in smaller cycles of rapid updates and promotes commitment into a single system rather than working in a silo. By contributing to a single system constantly, system-level bugs appear early where they are far more efficient to solve.
Through effective CI, developers can save large amounts of time on testing and debugging and instead focus on rapid design exploration. They are also able to react far quicker to changing markets and customer requirements ensuring that any designs remain cutting edge. Finally with Continuous Integration, designs are updated longer after initial deployment, meaning that we can use FPGA’s reconfigurability to constantly accelerate the latest and greatest algorithms
Combining CI with AI on FPGAs
Let us now look at how we can apply CI to effectively build and run AI on FPGAs. AI as a field is constantly improving both in terms of architectures used and in terms of refining and processing the data. This makes CI particularly effective when applied to AI development. Throughout the development process we may be constantly making tweaks to our architecture to improve accuracy or performance. To ensure that these tweaks are effective, we need to run tests efficiently and receive feedback quickly. Using CI, we can create an automated pipeline to deliver the results we need:
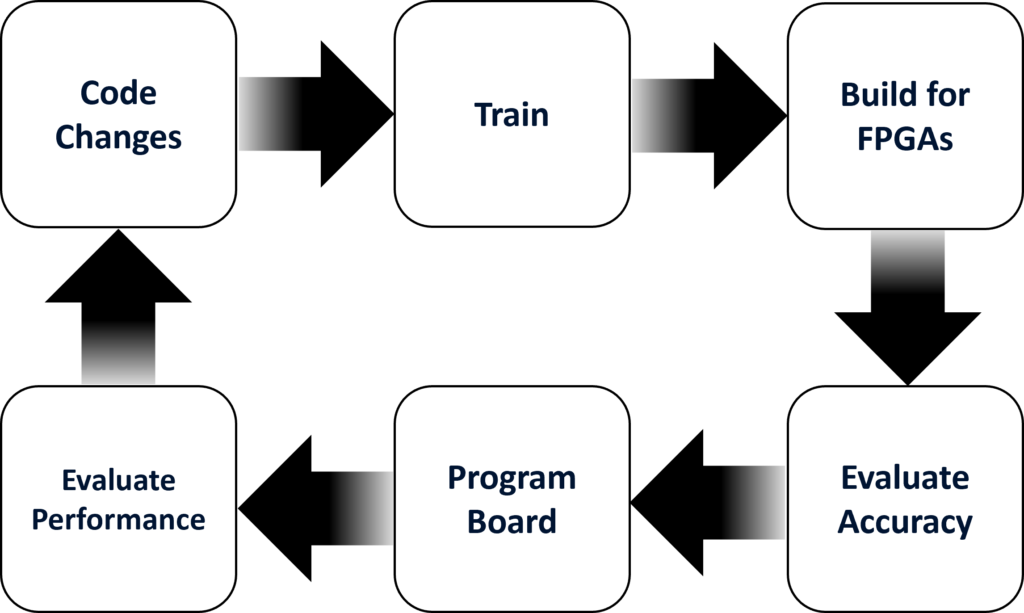
- Code Changes: Given results from our previous run, we modify our AI and commit the code changes. BeetleboxCI will then detect these changes and start the build and run pipeline.
- Train: The first step in our pipeline will be to retrain the AI.
- Build for FPGAs: Once trained we need to perform some specific steps to change the model so that it is accelerated effectively on FPGAs. Such steps include quantization to improve performance on the FPGA.
- Evaluate Accuracy: Once the new model is ready, we need to evaluate its accuracy to see if our changes had any noticeable impact. If the changes lowered accuracy, we may choose to adjust the model.
- Program Board: If the accuracy is acceptable, we then program our FPGA board.
- Evaluate Performance: By running the AI on the board, we can evaluate performance and see what speed ups our FPGA is able to achieve. Having gathered all this information, we can then refine the model again and boost performance.
Let’s get started
We have explored the process of combining CI with AI on FPGAs and why using CI on FPGAs is effective. We also explained that the computational efficiency, power consumption and future proofing make FPGAs a great choice for accelerating AI. With all this in mind, we will now look at a concrete example that can easily be run in minutes at home. We can get going by visiting the GitHub and following the instructions on the quick start user guide. In this first iteration, we will be focused on running our AI on the board itself, but will then look into integrating this workflow into a pipeline on BeetleboxCI.